Post Stastics
- This post has 1474 words.
- Estimated read time is 7.02 minute(s).
Newbie Developers, especially those who are self-taught, often struggle with graph algorithms. I recently helped a young man on slack get a handle on the subject and I thought I would share my insights with those of you who lack the ability to write breadth-first search (BFS) and depth-first search (DFS) algorithms from scratch. Knowing how to implement these two graph walking algorithms from scratch will make you a much better developer.
First, let me say that graph walking algorithms are not hard once you get the hang of them. The two basic techniques (BFS and DFS) are the bases for many graph algorithms and therefore are worth learning, and learning well! You should practice the basic implementations here until you understand them and can write them off the top of your head.
So let’s get started, shall we? The most common graph walking algorithm is Depth-First Search. It walks a graph from top to bottom. While there are several ways to implement this algorithm (i.e.: Iterative, recursive, and stack-based.), we will use the stack-based approach here.
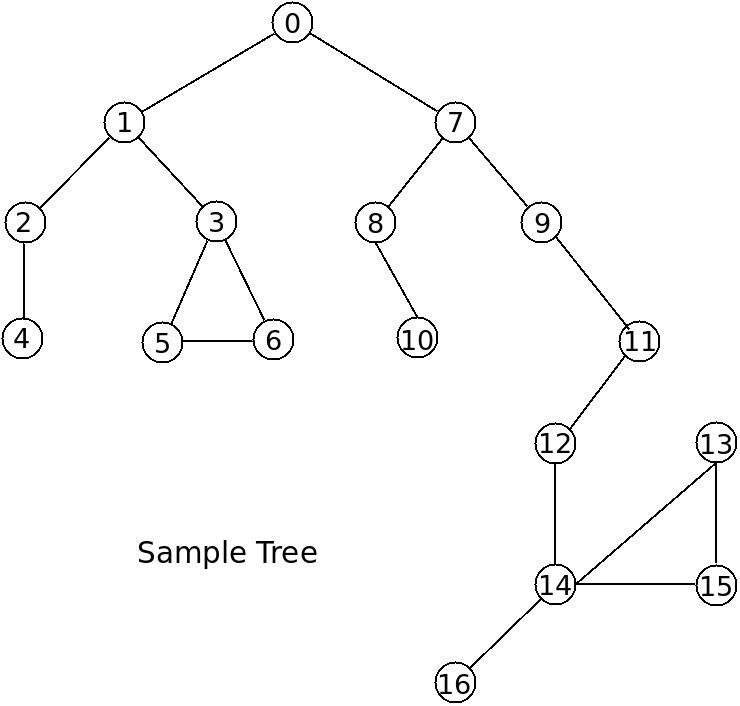
We will use the above tree as our sample graph.
A few things to note here is that our sample graph is cyclic. That is it contains two cycles or loops. The first formed by nodes 3, 5, and 6, and the second formed by nodes 14, 13, and 15. The other thing to notice is that this is a non-directed graph. That is that the edges (connecting lines) do not have a direction. So the connection from node 12 to node 14 is also a connection node 14 to node 12. In a directed graph the edges will typically have an arrow drawn in the direction of travel. That is to say that:
0–>1
would signify a path from node 0 to node 1 but, not a path from node 1 to node 0. You can think of directed edges as one-way streets and, non-directed edges as two-way streets. For today, we will stick to non-directed graphs for our traversal code.
If we want to walk this graph in a depth first mode we will begin at node 0 and move to node 1, then 2, then node 4, then back up to 2 and then move down to node 3, then 5 and then node 6. Then we would back up to node 0 and move down to node 7 and continue the pattern of moving down on the left side first, then when we reach a leaf node (a node that has no children) we back up to the next node with leaves that have yet to be visited.
Seems simple enough until you try to code it right? I recall the first time I came across this. I was clueless as to how to back up the graph. Finally, I found a sample of code in 6809 assembly language that demonstrated using a stack. Sitting down and working out a small graph using paper and pencil helped me understand how it was working. I recommend you do the same with the following code:
def dfs(graph, start):
visited = []
stack = []
stack.append(start)
while stack:
current = stack.pop()
if current in visited:
print(f'Node {current} already visited!')
continue
visited.append(current)
print(f'Visiting node: {current}')
neighbors = graph[current]
neighbors.reverse()
for neighbor in neighbors:
print(f'Pushing node: {neighbor}')
stack.append(neighbor)
if __name__ == '__main__':
graph = [[1,7], [2,3], [4], [5,6], [], [6], [], [8,9], [10],
[11], [], [12], [14], [15], [13, 15, 16], [], []]
start = 0
dfs(graph, start)
I have placed print statements in the code to help you understand the output as the program runs. The graph is represented using an adjacency list. Here, the parent node is implied by the sub-list position and, the sub-list contains the children of the parent. For example, the list containing the children of node 0 is in the zeroth position of the outer list.
If you run this code you’ll get the following output:
Visiting node: 0 Pushing node: 7 Pushing node: 1 Visiting node: 1 Pushing node: 3 Pushing node: 2 Visiting node: 2 Pushing node: 4 Visiting node: 4 Visiting node: 3 Pushing node: 6 Pushing node: 5 Visiting node: 5 Pushing node: 6 Visiting node: 6 Node 6 already visited! Visiting node: 7 Pushing node: 9 Pushing node: 8 Visiting node: 8 Pushing node: 10 Visiting node: 10 Visiting node: 9 Pushing node: 11 Visiting node: 11 Pushing node: 12 Visiting node: 12 Pushing node: 14 Visiting node: 14 Pushing node: 16 Pushing node: 15 Pushing node: 13 Visiting node: 13 Pushing node: 15 Visiting node: 15 Node 15 already visited! Visiting node: 16
The algorithm is simple: First we set up a list to keep track of the visited nodes. Next we set up a list to use as a stack. Then we initialize the stack with the first node to visit. In this case node zero.
Now, while the stack is not empty, we pop off the top element of the stack, and use it as the current element. Initially, the stack only contains one element, element zero. Then we check if the current element is in the list of visited nodes, if so, we skip it, otherwise we reach into the adjacency list and grab the current node’s children. We then place each of the children on the stack. Then we return to the top of the while loop to pop-off the next element, which will be the first child of the current node. Walk through this process on the tree above or start with a smaller tree if needed. But get a grasp of what is happening here!
You will notice that I make a call to neighbors.reverse() in the above code. This is not really needed and I did it so that the child nodes would be visited in left to right order. This improves the readability and makes the process easier to grok when comparing the tree, code, and output. If you step through the code you’ll begin to see how the stack allows us to place the current node’s children next in-line for processing. This ensures that the next node to be processed will be one level lower in the tree as long as the current node has children.
Walking the Graph Breadth First
OK, we’ve seen how to walk the tree in depth-first order. But, how do we walk it in a breath (width) first order? Would you believe we can use the same code? Well, OK, there is one minor change needed.
In the above code we used the stack to control which nodes we visited next. By placing the children of the current node next on the stack we ensured they would be visited next. But what if we used a queue? What happens then to the visitation ordering? Let’s give it a try and see. Below is the code using a Queue in place of the stack used earlier:
def bfs(graph, start):
visited = []
que = []
que.append(start)
while que:
current = que.pop(0)
if current in visited:
print(f'Node {current} already visited')
continue
print(f'Visiting node {current}')
visited.append(current)
neighbors = graph[current]
for neighbor in neighbors:
print(f'Queing: {neighbor}')
que.append(neighbor)
if __name__ == '__main__':
graph = [[1, 7], [2, 3], [4], [5, 6], [], [6], [], [8, 9], [10],
[11], [], [12], [14], [15], [13, 15, 16], [], []]
start = 0
bfs(graph, start)
If you run this code you’ll see it visits each node in a breadth-first manner. Below is the output from this program:
Visiting node 0 Queing: 1 Queing: 7 Visiting node 1 Queing: 2 Queing: 3 Visiting node 7 Queing: 8 Queing: 9 Visiting node 2 Queing: 4 Visiting node 3 Queing: 5 Queing: 6 Visiting node 8 Queing: 10 Visiting node 9 Queing: 11 Visiting node 4 Visiting node 5 Queing: 6 Visiting node 6 Visiting node 10 Visiting node 11 Queing: 12 Node 6 already visited Visiting node 12 Queing: 14 Visiting node 14 Queing: 13 Queing: 15 Queing: 16 Visiting node 13 Queing: 15 Visiting node 15 Visiting node 16 Node 15 already visited
Using the Queue changes the order in which we visit the nodes. With the Queue we are placing the children of the current node at the end of the queue. So, sibling nodes will be visited before the child nodes are visited. Simply swapping out the stack for a queue changes the order of visitation. Just what we wanted and, we only needed to learn one algorithms for walking the graph.
If you’re serious about becoming a software developer, I’d suggest you practice this simple code until it’s second nature. It’s the algorithm you want to learn, not necessarily the code. You may need to write this in languages other than python one day.
OK, But What Is This Good For?
Why did we go to all this trouble to learn to walk a graph? Well, graphs are a major concern in software development. Many real-world issues and systems can be modeled using graphs. For example, a shipping company may need to work out routes for their deliveries. A computer network can be modeled as a graph, or the connections between people can be modeled as a graph.
There are many operations that can be applied to the graph. Most of these are based on walking the graph in either a Depth-First or Breath-First manner. In future articles we will look at some of these operations and how they fit in with what we learned today.
Until then, Happy Coding!